Stochastic Gradient Descent¶
Minimize an objective function using a stochastic approximation of gradient descent.
Inputs
Data: input dataset
Preprocessor: preprocessing method(s)
Outputs
Learner: stochastic gradient descent learning algorithm
Model: trained model
The Stochastic Gradient Descent widget uses stochastic gradient descent that minimizes a chosen loss function with a linear function. The algorithm approximates a true gradient by considering one sample at a time, and simultaneously updates the model based on the gradient of the loss function. For regression, it returns predictors as minimizers of the sum, i.e. M-estimators, and is especially useful for large-scale and sparse datasets.
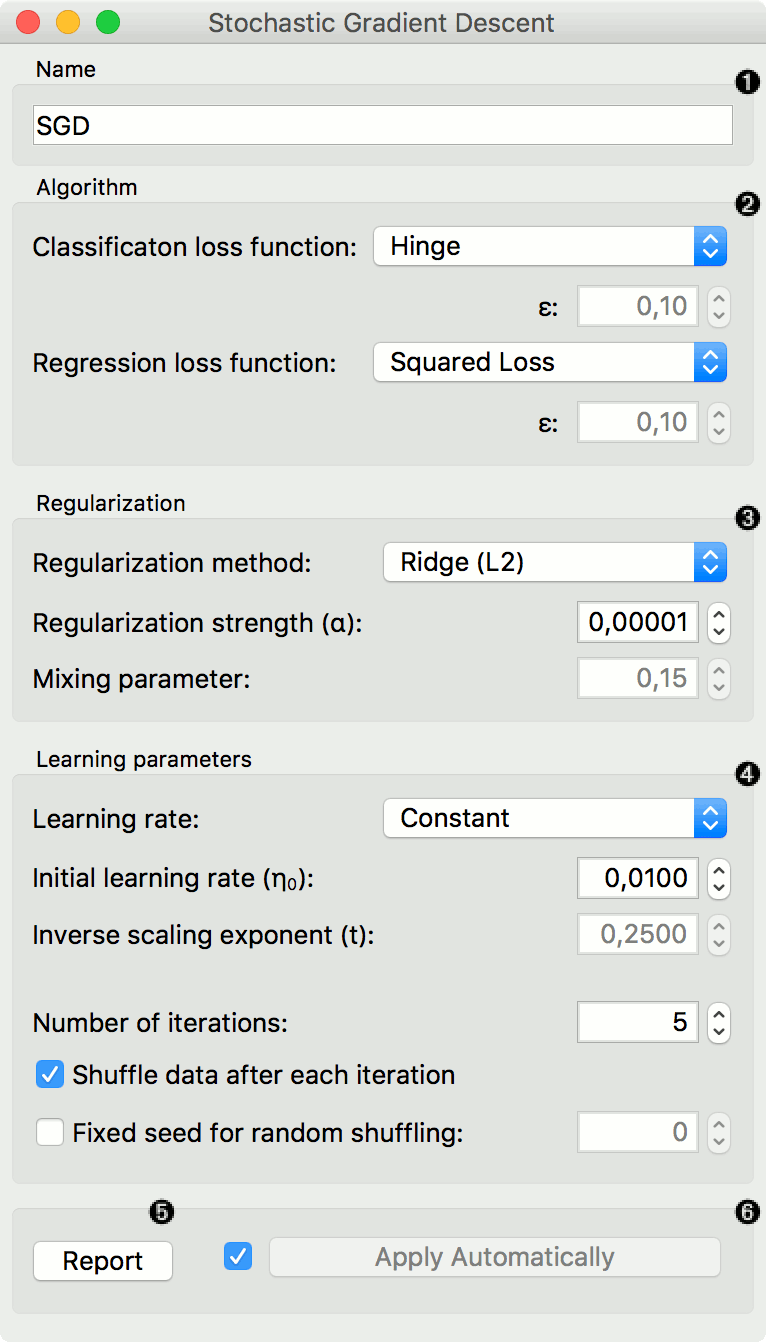
Specify the name of the model. The default name is "Stochastic Gradient Descent".
Loss function:
Classification:
Hinge (linear SVM), default.
Logistic Regression (logistic regression SGD)
Modified Huber (smooth loss that brings tolerance to outliers as well as probability estimates)
Squared Hinge (quadratically penalized hinge)
Perceptron (linear loss used by the perceptron algorithm)
Squared Loss (fitted to ordinary least-squares)
Huber (switches to linear loss beyond ε)
Epsilon insensitive (ignores errors within ε, linear beyond it)
Squared epsilon insensitive (loss is squared beyond ε-region).
Regression:
Squared Loss (fitted to ordinary least-squares), deafult.
Huber (switches to linear loss beyond ε)
Epsilon insensitive (ignores errors within ε, linear beyond it)
Squared epsilon insensitive (loss is squared beyond ε-region).
Regularization norms to prevent overfitting:
None.
Lasso (L1) (L1 leading to sparse solutions)
Ridge (L2) (L2, standard regularizer), default.
Elastic net (mixing both penalty norms).
Regularization strength defines how much regularization will be applied (the less we regularize, the more we allow the model to fit the data) and the mixing parameter what the ratio between L1 and L2 loss will be (if set to 0 then the loss is L2, if set to 1 then it is L1).
Optimization:
Learning rate:
Constant: learning rate stays the same through all epochs (passes), default.
Optimal: a heuristic proposed by Leon Bottou
Inverse scaling: earning rate is inversely related to the number of iterations
Initial learning rate.
Inverse scaling exponent: learning rate decay.
Number of iterations: the number of passes through the training data.
Tolerance: training will stop when current loss is within tolerance of best loss.
If Shuffle data after each iteration is on, the order of data instances is mixed after each pass.
If Fixed seed for random shuffling is on, the algorithm will use a fixed random seed and enable replicating the results.
Press Apply to commit changes. Alternatively, tick the box on the left side of the Apply button and changes will be communicated automatically.
Preprocessing¶
SGD uses default preprocessing when no other preprocessors are given. It executes them in the following order:
removes instances with unknown target values
continuizes categorical variables (with one-hot-encoding)
removes empty columns
imputes missing values with mean values
normalizes the data by centering to mean and scaling to standard deviation of 1
To remove default preprocessing, connect an empty Preprocess widget to the learner.
Feature Scoring¶
Stochastic Gradient Descent can be used with Rank for feature scoring. See Learners as Scorers for an example.
Examples¶
For the classification task, we will use iris dataset and test two models on it. We connected Stochastic Gradient Descent and Tree to Test & Score. We also connected File to Test & Score and observed model performance in the widget.

For the regression task, we will compare three different models to see which predict what kind of results. For the purpose of this example, the housing dataset is used. We connect the File widget to Stochastic Gradient Descent, Linear Regression and kNN widget and all four to the Predictions widget.
